一份長達166頁的《最新中國人工智能開源軟件發展白皮書》(以下簡稱《白皮書》)正式發布,全面梳理了我國在人工智能(AI)開源軟件領域的發展現狀、核心挑戰與未來趨勢,尤其對人工智能基礎軟件開發這一關鍵環節進行了深度剖析。該報告不僅是一份詳實的技術與產業分析,更是指引未來方向的重要參考。以下是對其核心內容的解讀。
一、發展現狀:生態初具規模,基礎軟件成為關鍵發力點
《白皮書》指出,中國AI開源軟件生態在過去幾年實現了跨越式發展。從模型框架、算法庫到工具鏈,開源項目數量與質量顯著提升,形成了以百度飛槳(PaddlePaddle)、華為MindSpore、一流科技OneFlow等為代表的自主核心框架陣營,并在國際社區中影響力日益增強。
與繁榮的上層應用開發相比,人工智能基礎軟件開發仍是整個生態體系的“基石”與“短板”。這主要包括:
- 底層計算框架與編譯器:負責將高級AI模型描述高效映射到多樣化的硬件(如GPU、NPU、CPU),其性能與易用性直接決定上層應用的效率與成本。
- 自動化工具鏈:涵蓋模型訓練、壓縮、部署、監控的全流程工具,是AI工程化落地的核心支撐。
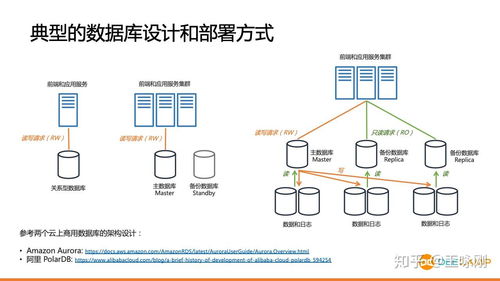
- 系統級優化與中間件:包括分布式訓練系統、高性能算子庫、數據管理與調度系統等,關乎大規模AI任務的可擴展性與穩定性。
《白皮書》顯示,我國在這些基礎軟件層雖已有布局,但在核心技術原創性、跨平臺適配能力、與國際頂級項目的生態協同方面,仍有提升空間。
二、核心挑戰:技術、生態與人才的三重考驗
報告深入分析了當前面臨的主要挑戰:
- 技術自主與創新壓力:在AI基礎軟件的核心架構、編程范式、編譯優化等領域,仍需突破關鍵理論與技術瓶頸,實現從“可用”到“好用”、“領先”的轉變。硬件異構性的加劇(多種AI芯片并存)也對基礎軟件的跨平臺適配與性能優化提出了極高要求。
- 開源生態構建與治理:健康的開源生態需要活躍的社區貢獻、清晰的知識產權協議、可持續的商業模式以及開放的合作文化。如何吸引全球開發者,形成強有力的上游貢獻,并建立中國主導的開源項目治理范式,是長期課題。
- 復合型人才短缺:AI基礎軟件開發需要既精通深度學習算法,又深諳計算機體系結構、操作系統、編譯原理等系統知識的頂尖人才。目前這類復合型、戰略型人才儲備嚴重不足。
三、未來趨勢:協同、開源與標準化
基于現狀與挑戰,《白皮書》展望了人工智能基礎軟件的未來發展路徑:
- “軟硬協同”設計成為主流:未來AI基礎軟件將與國產AI芯片等硬件深度耦合,通過硬件感知的編譯優化、定制化算子庫等方式,釋放硬件最大算力,形成自主可控的“算力底座”。
- 開源與開放成為創新核心引擎:開源不僅是代碼共享,更是協作創新的平臺。預計將有更多企業、高校和科研機構將基礎軟件項目開源,通過社區力量加速迭代,并積極參與國際開源基金會(如LF AI & Data基金會),提升話語權。
- 標準化與模塊化降低開發門檻:針對模型格式、接口、部署環境等制定行業或國家標準,促進不同基礎軟件組件之間的互聯互通。基礎軟件將趨向模塊化、微服務化,讓開發者能像搭積木一樣構建AI系統,降低使用和二次開發難度。
- 聚焦“AI for Science”與“大模型”等新范式:基礎軟件需要適應科學研究、超大規模預訓練模型等新興場景的需求,在分布式訓練效率、內存優化、超大模型支持等方面進行前瞻性布局。
四、與啟示
這份166頁的《白皮書》系統性地揭示了一個核心觀點:人工智能的競爭,不僅是算法與數據的競爭,更是基礎軟件平臺與生態的競爭。夯實基礎軟件開發,對于提升我國AI產業的核心競爭力、保障技術安全、培育原創性創新具有戰略意義。
對于產業界而言,需要加大長期投入,耐住寂寞攻克底層技術;對于學術界,應鼓勵跨學科研究,培養系統級AI人才;對于開發者社區,積極參與開源貢獻,共同繁榮生態。唯有在基礎軟件這一“根技術”上深耕不輟,中國人工智能的參天大樹才能枝繁葉茂,在全球數字浪潮中立于不敗之地。